Customer Analytics
Summary:
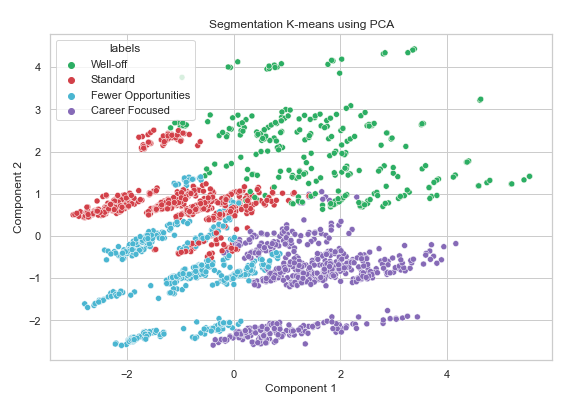
- Data fragmented into 4 Segments using a combination of Principal Component Analysis (4 Components) and K-Means Clustering.
- Career-focused - Young group of high-income and well-qualified people.
- Well-off - Mid-Age wealthy group in a big city.
- Standard - Average Population. (Middle Class)
- Few opportunities - Customers from small cities with mediocre income and not highly qualified.
- A Descriptive Analysis of the Number of purchases, Brand choice, and Revenue generated per segment.
- Price Elasticities (Modelled the elasticities for each price point starting 0.5 to 3.5, for 300 values.)
- Purchase Probability -
- Customers from Well-off & Career-Focused segments are less elastic.
- Customers are less sensitive to price changes when there are promotions.
- Beneficial to have a higher original price and constant promotions.
- Brand Choice Probability (cross-brand) -
- Brand 5 can reduce its price by 1% to gain its market share from Well-off segments.
- Career-Focused Segment are loyal customers of Brand 5.
- Brand 1 has to reduce its price by 2% to gain some market share from Brand 2 in the Standard and Few Opportunities Segments.
- Purchase Probability -
Resources
- Python Version: 3.7
- Packages: pandas, numpy, sklearn, scipy
- Visualizations: matplotlib, seaborn
- Techiques: Linear Regression, Logistic Regression, K-Means Clustering, Principal Component Analysis
- Full Code can be accessed at the Github repository